DeepSeek Engram: AI Memory Breakthrough Solving Billion-Dollar Crisis
Aditya Kachhawa

Why is AI so expensive?
That simple question determines which startups survive, which countries dominate the AI race, and why your chatbot costs $20 a month. In mid-January 2026, DeepSeek quietly published a research paper on GitHub that might finally answer it.
The paper is called Engram and it proposes something deceptively simple: stop forcing AI models to "re-think" what they already know. Give them real memory instead.
This isn't just clever engineering. It's a fundamental shift in how AI systems could work one that directly targets the most expensive bottleneck in the industry: memory.
Here's the truth nobody talks about: in the AI era, compute gets headlines. But memory decides who wins.
Engram in 10 Seconds
For readers who need the essentials:
The Problem: AI models waste expensive GPU compute re-calculating simple facts instead of remembering them
The Solution: Engram separates memory (cheap RAM) from reasoning (GPU work)
The Tech: Uses fast O(1) lookup so AI retrieves facts like a library not re-deriving every time
The Impact: Higher long-context accuracy, cheaper inference, less reliance on scarce HBM
Bottom Line: AI gets more capable without getting proportionally more expensive by learning the difference between remembering and thinking
The Crisis: AI's Memory Problem
AI's biggest bottleneck isn't intelligence, it's infrastructure economics.
Modern AI depends heavily on HBM (High Bandwidth Memory), the ultra-fast memory sitting next to GPUs. HBM is expensive, scarce, and increasingly contested as AI demand explodes. Industry warnings suggest memory pricing pressure could last well into 2027, largely because AI infrastructure keeps consuming supply faster than production can expand.
The market has already shown it understands this. When DeepSeek released its R1 model on January 20, 2025, the market reacted dramatically. On January 27, 2025 now known as "DeepSeek Monday" the news triggered the largest single-day stock selloff in tech history, with NVIDIA alone losing nearly $600 billion in market cap (17% drop). This proved that AI economics can move markets as forcefully as AI capability headlines.
But here's the deeper problem most people miss:
When you ask an AI "What's the capital of France?", it doesn't remember - Paris the way a human does. Instead, it reconstructs the answer by running repeated computation through layers of the model again and again.
It's like hiring a mathematician to repeatedly solve 2+2 instead of writing it down once.
Multiply that inefficiency across billions of daily queries and growing context windows, and you don't just get slower AI, you get a cost curve that becomes impossible to sustain.
Enter Engram: Memory Meets Intelligence
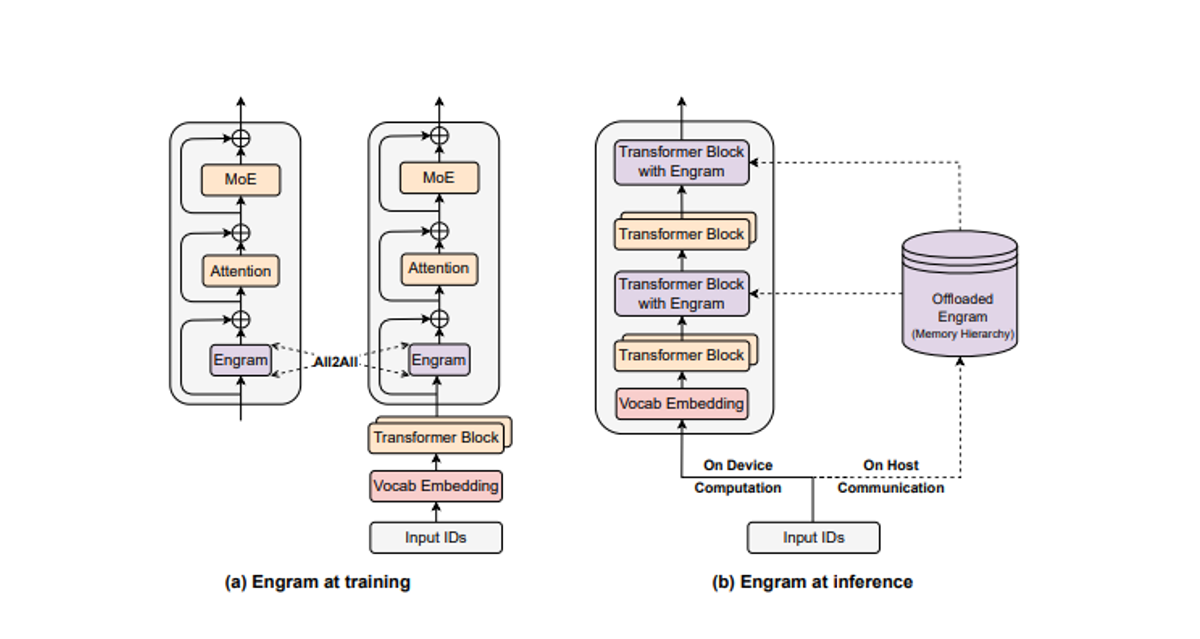
DeepSeek's Engram introduces a conditional memory module that separates static knowledge storage from dynamic computation so facts can live in cheaper system RAM while GPUs focus on genuine reasoning.
Think of it this way:
Traditional AI: Your brain has to re-derive every fact from scratch
AI with Engram: Your brain has a library look up facts instantly and save thinking power for real problems
How It Works (Simply Explained)
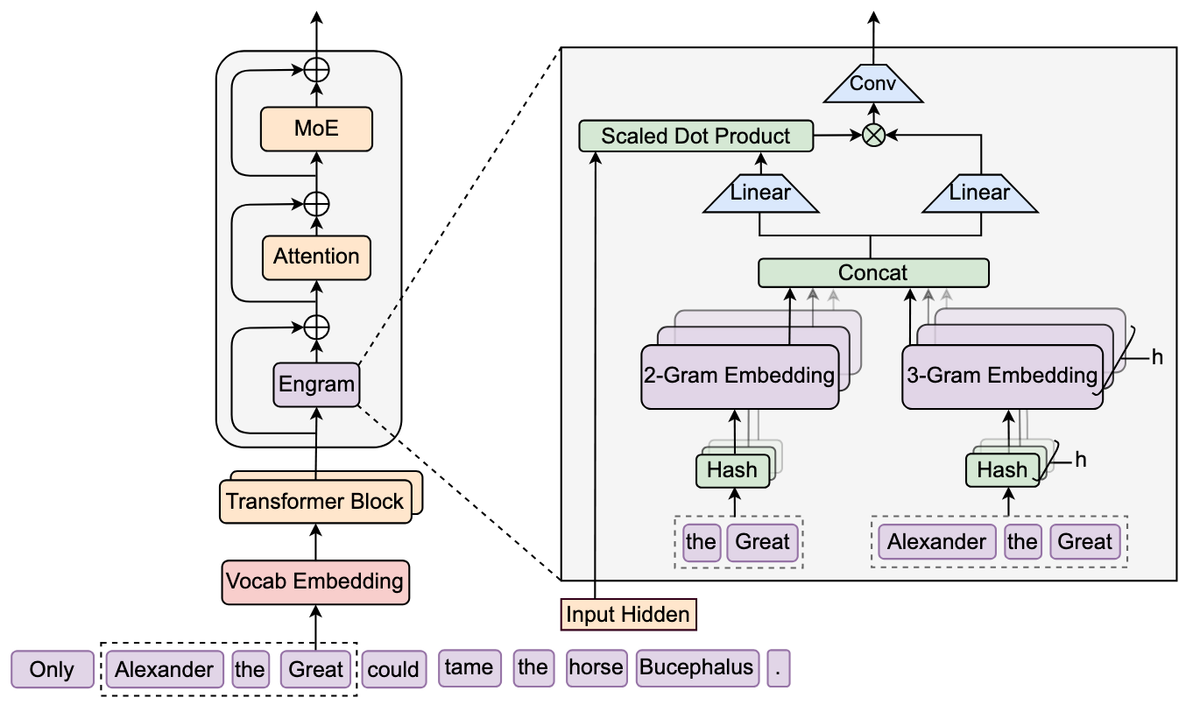
Smart Storage
Engram uses tokenizer compression to reduce vocabulary size by 23%, making memory storage more efficient. Knowledge patterns are stored in normal system RAM instead of premium GPU memory.
Intelligent Retrieval
It uses Multi-Head Hashing to reduce confusion for example, ensuring "Universal" isn't mistaken for "Universal Studios." It's like a librarian who checks context before handing you the wrong book.
Context-Aware Gating
Before injecting retrieved information, Engram verifies it matches the active conversation context reducing irrelevant retrieval.
The Sweet Spot
DeepSeek reports the best balance comes from allocating 20–25% of model capacity to Engram memory and 75–80% to traditional reasoning parameters.
Real-World Impact: Why This Matters Now
Consider a banking compliance chatbot handling 10 million customer queries daily.
Under traditional architecture, when customers ask common questions like "What are your wire transfer fees?" or "How long does processing take?", the model repeatedly burns GPU cycles reconstructing stable policy facts thousands of times per minute.
With Engram, those facts sit in a DRAM lookup table. Retrieval becomes fast and cheap, freeing the GPU to focus on the expensive work that actually matters: complex exceptions, fraud signals, multi-step workflows, and personalized financial guidance.
In environments dominated by repetitive, fact-heavy queries, this kind of memory-first architecture could reduce inference costs materially and just as importantly improve latency and reliability. Multiply this across airlines (policies), e-commerce (returns), and healthcare (coverage rules), and the appeal becomes crystal clear: Engram doesn't just make AI faster. It makes AI more deployable at scale.
The Results That Matter
DeepSeek tested Engram with a 27 billion parameter model. The reported gains are eye-opening:
Long-Context Accuracy: 97% accuracy on "Needle in a Haystack" benchmarks vs. 84.2% for traditional models
Knowledge Tasks: +3.4 to +4 points improvement (MMLU, CMMLU)
Reasoning: +3.7 to +5 points improvement (BBH, ARC-Challenge)
Coding & Math: +2.4 to +3.0 point gains (HumanEval, MATH, GSM8K)
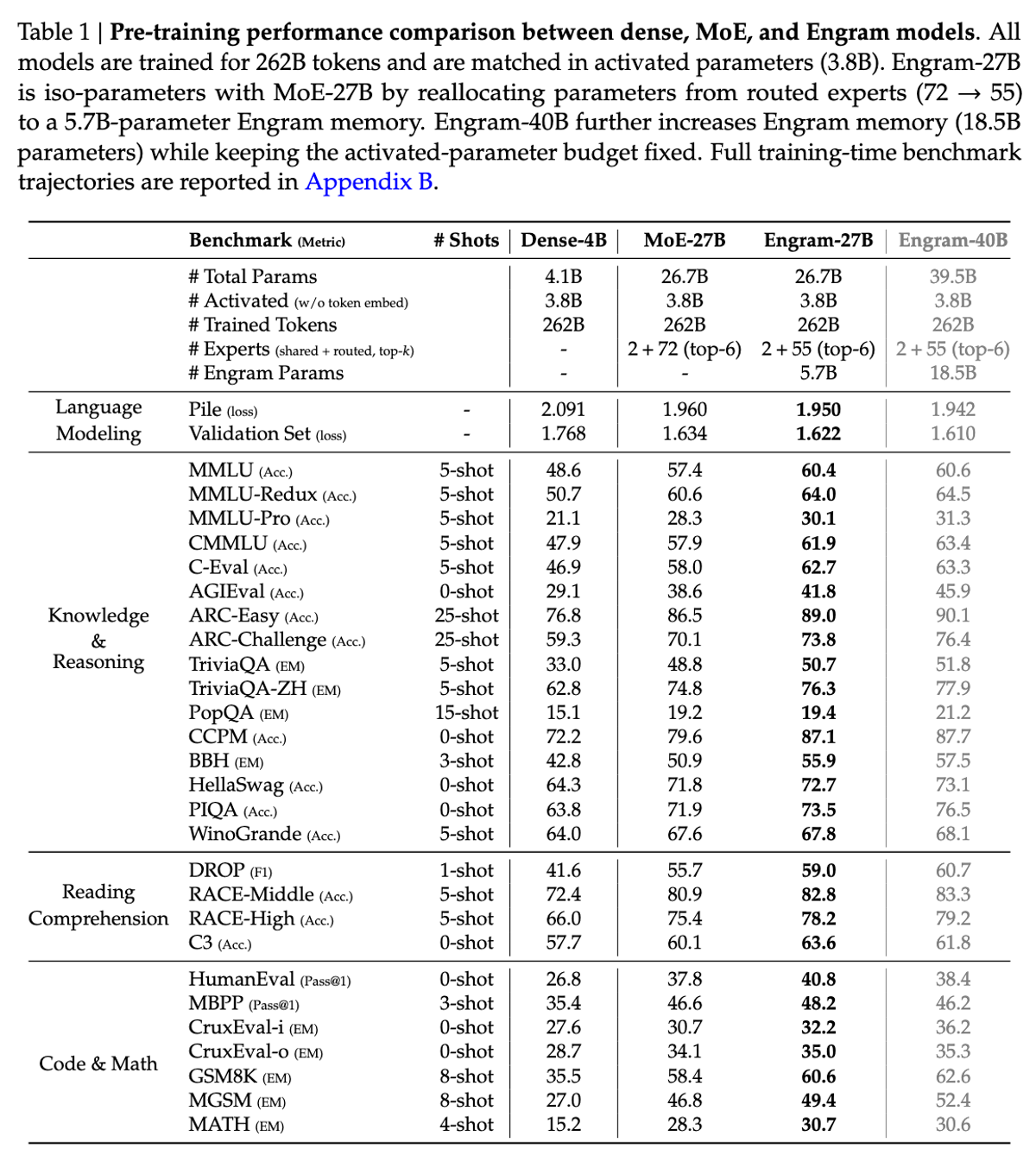
The Key Insight: Performance scales linearly with memory size meaning more memory can yield better results without proportionally increasing compute.
That's the breakthrough. It suggests intelligence can scale not just by buying more compute, but by allocating more memory often a cheaper and easier resource to expand.
Important Note: These results come from a 27B parameter model. Whether Engram maintains these gains at much larger scales (100B+ parameters) remains an open question, as the paper notes this as an area for future research.
Why This Changes Everything
Economics: From Scarcity to Abundance
Engram reduces reliance on scarce, expensive HBM by storing knowledge in cheaper DRAM/system RAM. That isn't a minor optimization, it fundamentally changes where the cost bottleneck lives.
Consider an AI deployment processing 10 billion tokens per day. Traditional architectures push nearly all requests through expensive transformer compute. Engram introduces a different option: if a meaningful slice of traffic is repetitive factual retrieval, those queries can shift toward O(1) memory lookups and away from GPU-heavy recomputation.
At datacenter scale, even moderate reductions in compute-per-token translate into lower GPU requirements, less cooling load, and reduced power draw especially on the highest-frequency queries. The result is a more flexible economics model where performance can improve without needing to scale GPU fleets at the same rate.
If you're deploying AI at scale, this translates to lower infrastructure costs, faster rollouts across more hardware profiles, and less exposure to HBM supply constraints.
Performance: Better AI for Everyone
That 97% long-context score isn't just academic. In practice, it means an AI assistant that's far less likely to lose track in long documents, multi-hour conversations, or multi-step workflows. It's the difference between "helpful, but requires constant correction" and "reliable enough to delegate real work."
Architecture: A New Paradigm
Engram suggests AI models should increasingly behave like systems with specialized modules: memory components for knowledge, reasoning components for computation, and retrieval pathways that reduce waste.
This mirrors how every successful computing platform evolved through memory hierarchies, caching, and architectures designed around cost-performance tradeoffs.
The Mechanism: How Engram Actually Works
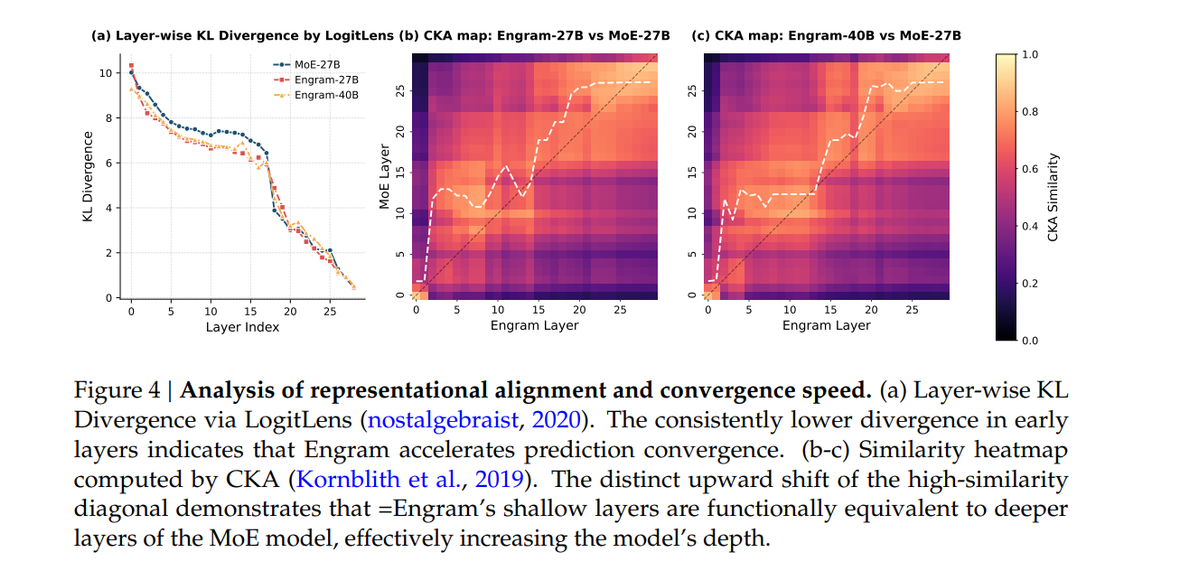
DeepSeek's research reveals something fascinating: Engram doesn't just store facts, it fundamentally changes how the model processes information.
Through LogitLens analysis, researchers found that Engram-equipped models reach "prediction-ready" states much faster than traditional models. The KL divergence (a measure of how close a layer is to the final answer) drops more steeply in early layers, meaning the model spends less depth reconstructing basic facts.
Even more revealing: Centered Kernel Alignment (CKA) analysis shows that Engram's layer 5 produces representations equivalent to a traditional model's layer 12. By offloading static pattern reconstruction to memory lookups, Engram effectively deepens the network preserving those layers for complex reasoning instead of wasting them on simple recall.
What's Next: DeepSeek V4 and Industry Response
Important Disclaimer: According to industry reports and anonymous sources, DeepSeek V4 is rumored to launch around mid-February 2026, possibly near Lunar New Year (February 17). There are strong signals that Engram may be integrated into this architecture based on the timing of the paper's release. However, DeepSeek has not officially confirmed this timeline or feature set.
If V4 ships with Engram integrated and performs well in production, Engram moves from "interesting research" to "competitive necessity."
DeepSeek's track record from V3 in December 2024 to the market-disrupting R1 in January 2025 suggests these papers aren't academic exercises. They're often previews of what ships next.
The question for OpenAI, Anthropic, and Google becomes urgent: Can this be replicated quickly and can it be done cleanly at scale?
Because whoever masters AI memory architecture gains leverage over inference latency, deployment cost, model consistency, and ultimately, product economics.
What Engram is NOT
Before the hype cycle distorts reality, here's what Engram does not claim to be:
Not a reasoning breakthrough - it doesn't magically improve creativity or logic. It improves fact retrieval efficiency.
Not a replacement for RAG - Engram is internal memory; RAG pulls external updated sources. They can complement each other.
Not eliminating GPUs - reasoning, training, and high-end inference still require serious compute.
Not a magic hallucination fix - wrong memory can be retrieved confidently if stored incorrectly.
Not proven at frontier scale yet - 27B shows promise, but scaling to very large frontier models (100B+) remains an engineering test.
Not a replacement for continual learning - Memory is frozen at training time; Engram can't access information added after training without retraining.
The Challenges Ahead
Not a Silver Bullet
Memory retrieval requires correct indexing and disambiguation. Errors may appear confident and be harder to detect than standard hallucinations.
Implementation Complexity
Engram demands careful memory management, fast hashing, context-aware gating, and training approaches that distribute knowledge between memory and weights effectively.
The Hidden Cost
Shifting AI scaling from HBM to DRAM could create new pricing pressure in system memory markets solving one constraint while pushing another.
Production Unknowns
Benchmarks are curated. Real deployment involves edge cases, multilingual inputs, adversarial prompts, and security concerns around memory injection.
Scale Uncertainty
All reported benchmarks come from a 27B parameter model. The paper acknowledges that whether Engram maintains these gains at frontier scales (100B+ parameters) requires further research.
Scaling Laws: The U-Shaped Discovery
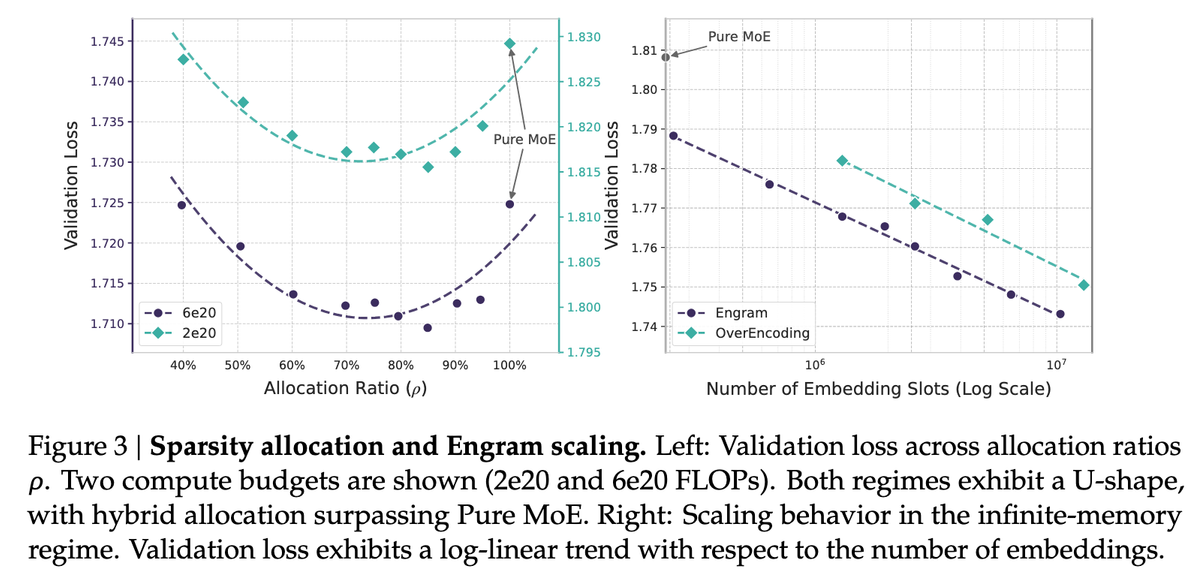
One of the paper's most important findings is the U-shaped scaling law that emerges when allocating capacity between MoE experts and Engram memory.
When DeepSeek tested different allocation ratios under fixed compute budgets, they discovered that pure MoE (100% allocation to experts) is actually suboptimal. The sweet spot? Allocating roughly 75-80% to MoE experts and 20-25% to Engram memory consistently produced the lowest validation loss.
This U-shape reveals something fundamental: memory and computation aren't substitutes, they're complements. Too much memory without computation fails. Too much computation without memory wastes resources. The optimal blend unlocks capabilities neither can achieve alone.
Long-Context Performance: Where Engram Shines
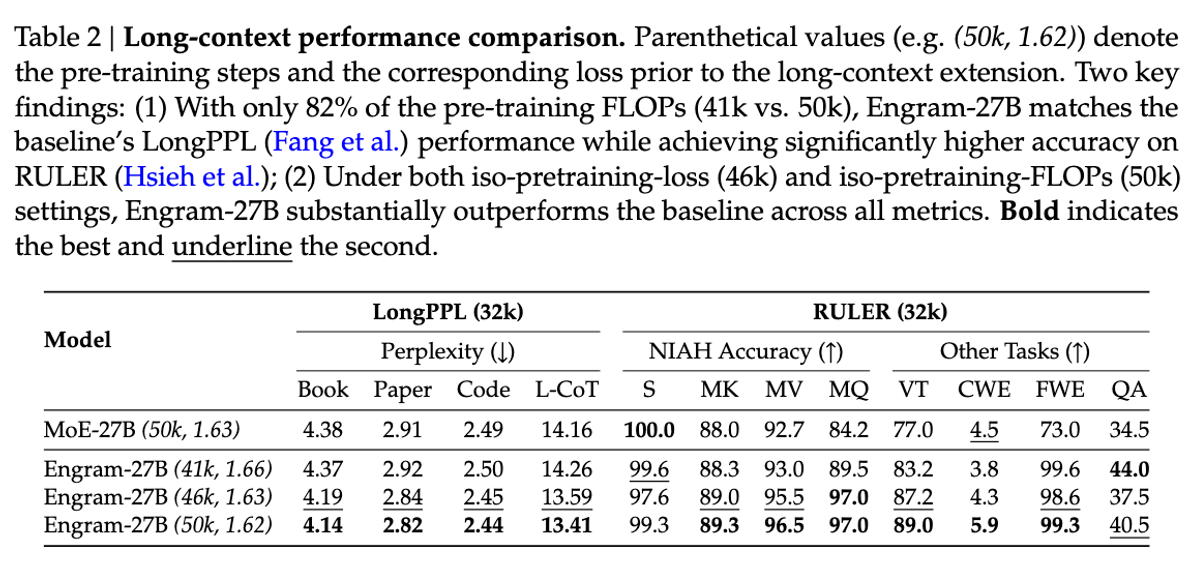
While Engram's improvements on standard benchmarks are impressive, its long-context performance is remarkable.
On the RULER benchmark's Multi-Query Needle-in-a-Haystack task, Engram achieved 97.0% accuracy compared to the baseline's 84.2%, a 12.8 point jump. On Variable Tracking, the gap was 89.0% vs 77.0%.
The explanation lies in attention mechanics. By delegating local dependencies to memory lookups, Engram frees attention capacity to focus on global context. The model doesn't waste attention heads tracking simple patterns like "Alexander the Great" it retrieves that instantly and uses attention for the hard stuff.
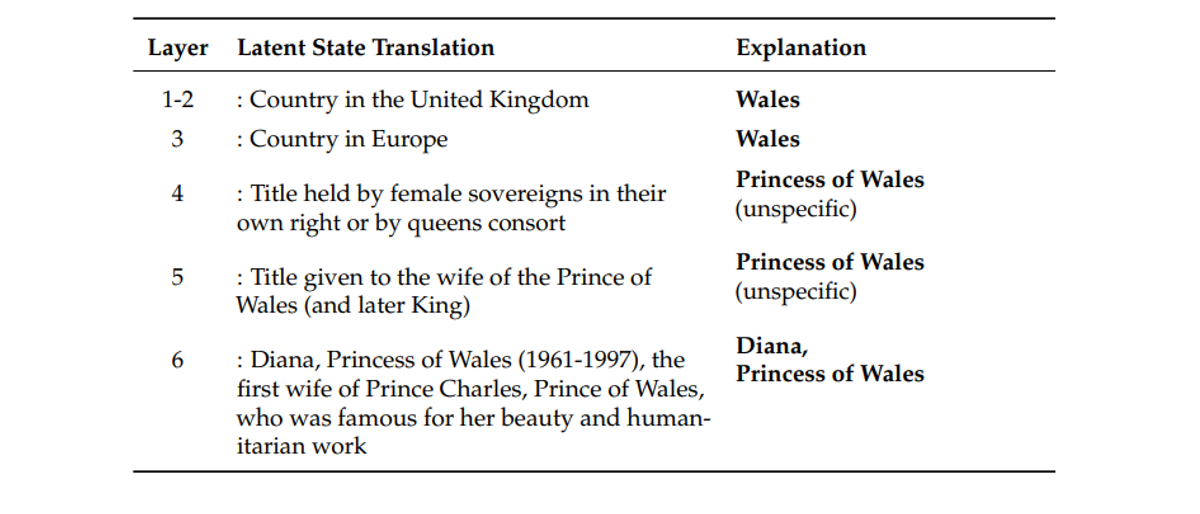
Case Study: Watching Engram Work

The paper includes fascinating visualizations of Engram's gating mechanism in action. The heatmaps show exactly when Engram activates and the pattern is striking.
In English text, Engram lights up on multi-token entities ("Alexander the Great," "Princess of Wales") and formulaic phrases ("By the way," "the Milky Way"). In Chinese, it identifies idiomatic expressions and historical entities with equal precision.
This confirms the design works as intended: Engram recognizes stereotyped linguistic patterns and handles them via lookup, relieving the Transformer backbone from memorizing these static associations.
The Bottom Line
For years, AI progress meant one thing: make the brain bigger.
Engram suggests a different approach: give the brain a library.
That shift between remembering and thinking matters because it changes AI economics. It decouples static knowledge from expensive compute and offers a path toward scaling capability without scaling GPU cost at the same rate.
If Engram delivers in real products, AI tools could become faster, cheaper, and more reliable not through magic, but through architecture.
And in computing history, architectural shifts are the ones that tend to last.
What to Watch Next (30–60 Days)
Five signals that will tell us whether Engram is the next major architecture shift or just a promising paper:
- DeepSeek V4 launch architecture – Rumored for mid-February 2026. If Engram is integrated and holds up under production load, competitors will need a response.
- Scaling beyond 27B parameters – Does it preserve gains at much larger model sizes? This is explicitly noted as future work in the paper.
- DRAM price movements – Watch DDR5/server memory markets for early pressure as AI shifts from HBM to system RAM.
- Nvidia's response – Roadmaps around hybrid memory architectures vs pure HBM expansion will signal industry direction.
- Competitive implementations – Whether OpenAI, Anthropic, or Google ship similar "conditional memory" systems quietly will matter more than press statements.
The revolution won't be shouted. It'll be quietly committed to GitHub like Engram was around January 12-13, 2026.
For technical readers: Check the Engram GitHub repository for implementation details.
For everyone else: Watch for DeepSeek V4. If Engram ships inside and the economics hold, the AI landscape may have just shifted again.
Sources
DeepSeek-AI Engram (GitHub Repository, Jan 2026)
DeepSeek Engram Paper — arXiv:2601.07372 (PDF)
Tom's Hardware technical analysis
Reuters market coverage (DeepSeek AI stock selloff - January 27, 2025)
Frequently Asked Questions
What is DeepSeek Engram?
DeepSeek Engram is a memory system for AI that helps models store and retrieve facts efficiently instead of recomputing them every time they're needed.
What problem does Engram solve?
It reduces wasted GPU compute by separating fact memory from reasoning, making AI cheaper and faster to run at scale.
How does Engram work in simple terms?
Engram stores knowledge in cheap RAM and uses fast O(1) lookup to fetch facts instantly during inference, rather than forcing the model to reconstruct them through expensive layer-by-layer computation.
Is Engram the same as RAG?
No. RAG (Retrieval-Augmented Generation) uses external documents or vector databases that can be updated, while Engram is an internal memory module built into the model itself during training.
Is Engram the same as KV cache?
No. KV cache speeds up token generation within a single conversation session, while Engram is designed for memory-style retrieval of stable knowledge across all queries and sessions.
Will Engram reduce hallucinations?
Not guaranteed, but it can improve factual consistency by retrieving stored knowledge more reliably than recomputation. However, if the stored memory is incorrect, it will be retrieved confidently, potentially making errors harder to detect.
Why does HBM matter for AI cost?
HBM is the expensive high-speed memory next to GPUs. Global shortages and high prices make AI infrastructure costly to scale, which is why alternatives like Engram's use of cheaper DRAM/system RAM matter economically.
Has Engram been tested on large models?
The research tested Engram on a 27 billion parameter model. Scaling to frontier models (100B+ parameters) and proving the approach works at that scale remains future work, as acknowledged in the paper.
Also Read
- Gemini vs ChatGPT vs DeepSeek: Which AI Dominates India 2026?
- What is Agentic AI? The Technology Replacing Apps in 2026
- Why Your Encrypted Data Is Already at Risk
About TechAffiliate.in
We decode breakthrough technologies and AI innovations into clear, engaging insights, whether you're a developer, tech professional, or simply curious about the future shaping our world.
Found this helpful? Share it with others!
Affiliate Disclosure
TechAffiliate may earn a commission if you purchase through our links. This helps support our work but does not influence our reviews. We always provide honest assessments of all products.
Related Articles
 AI & Machine Learning
AI & Machine LearningDec 25, 2025 • 17 min read
56% Salary Jump: 7 AI Skills That Got Indians ₹7L Raises
Indian professionals with AI skills earn 56% more (₹12L to ₹19L+). Learn the 7 most in-demand AI skills in 2026, with step-by-step learning paths, free resources, and real salary data from ₹6.6L to ₹2.6Cr.
 AI & Machine Learning
AI & Machine LearningDec 30, 2025 • 16 min read
DeepSeek vs ChatGPT vs Gemini 2026: Which AI is Better? (Tested 30 Days)
Gemini topped India's AI searches in 2025. I tested GPT-5.2, Gemini 3 Flash, and DeepSeek V3.2 for 30 days. Real results, privacy warnings, honest winner.
 AI & Machine Learning
AI & Machine LearningJan 14, 2026 • 11 min read
The Intelligence You've Stopped Noticing
Ambient AI doesn't wait for your commands it watches, learns, and acts in the background. The systems you've stopped noticing are making thousands of decisions on your behalf. What happens when convenience becomes drift?
 AI & Machine Learning
AI & Machine LearningJan 19, 2026 • 13 min read
Google's Universal Commerce Protocol: Why Affiliate Marketing Will Die in 2026 ?
Google's UCP lets AI buy products directly. Affiliate marketers have 12-24 months to adapt. Here's why traditional attribution breaks and what to do.
Comments (0)
Leave a Comment
No comments yet
Be the first to share your thoughts!