GLM-5.2 Review (2026): Benchmarks, Free Access & How to Use It
Aditya Kachhawa

If you've been keeping up with AI news lately, you've probably noticed a new name showing up everywhere GLM-5.2. And there's a good reason for that. This is not just another model release. It's the moment open-source AI genuinely caught up to the big players.
Let me break it all down for you no jargon overload, no marketing fluff. Whether you're a developer who lives in the terminal or someone who just wants a free ChatGPT alternative that actually works, this guide has you covered.
What Is GLM-5.2?
GLM-5.2 is a large language model made by a Chinese AI company called Z.ai (previously known as Zhipu AI). They were spun out of Tsinghua University, one of China's top tech schools.
It was announced on June 13, 2026, and the weights were made publicly available on June 16–17, 2026 on Hugging Face.
According to Artificial Analysis, an independent AI research firm, GLM-5.2 is currently the #1 open-weights AI model in the world and 4th best overall, behind only a couple of OpenAI and Anthropic models. And it's completely free to download and use.
That's a big deal.
Quick Specs (The Key Numbers)
Don't worry if some of these don't mean much yet - I'll explain the important ones below.
| What | Details |
|---|---|
| Developer | Z.ai (formerly Zhipu AI) |
| Released | June 13–17, 2026 |
| Total Parameters | ~744–753 Billion (MoE architecture) |
| Active Parameters Per Query | ~40 Billion |
| Context Window | 1,000,000 tokens (1 million!) |
| Max Output | ~128,000 tokens |
| License | MIT — fully free, even for commercial use |
| Languages | English + Chinese |
| Thinking Modes | High (fast) and Max (deep) |
| API Pricing | $1.40 input / $4.40 output per 1M tokens |
↔️ Scroll horizontally to see all columns
Why Should You Care? (What Makes This Special)
1. The Context Window Is Huge and Actually Works
"Context window" is just the amount of text an AI can read and remember in one go. Most models cap out at around 128,000–200,000 tokens. GLM-5.2 supports 1 million tokens.
To put that in perspective: 1 million tokens is roughly 750,000 words that's about seven average-length novels, or an entire large codebase with hundreds of files.
More importantly, Z.ai didn't just slap a big number on the box. They actually trained the model to use that context reliably for long, complex tasks which is the hard part most companies skip.
2. It's a Massive Jump in Coding Performance
The previous version, GLM-5.1, was already decent. But GLM-5.2 made a jaw-dropping improvement on one of the most important coding benchmarks:
- DeepSWE score: 18 → 46.2 (a 28-point jump in one release)
DeepSWE tests whether an AI can actually solve real software engineering problems not toy examples, but the kind of messy, multi-file bugs you'd find in a real codebase. A 28-point improvement in a single release is genuinely unusual.
3. You Can Choose How Hard It Thinks
GLM-5.2 has two reasoning modes:
- High mode --> Responds faster, uses fewer tokens. Great for everyday tasks like writing functions, debugging small issues, or answering questions.
- Max mode --> Uses deeper reasoning, more compute time. For the complex stuff: refactoring a whole system, planning an architecture, or solving hard algorithmic problems.
This matters practically because the "think harder" mode uses around 43,000 tokens per task. That adds up in cost. Having the option to dial it down when you don't need it is smart design.
4. MIT License --> Completely Free, No Strings Attached
Most AI models from big companies are closed. You can use their API, but you don't own anything. GLM-5.2 is released under the MIT license, which means:
- Download it and run it on your own computer/server
- Use it in commercial products you sell
- Modify and fine-tune it however you want
- No royalties, no usage fees, no calling home to Z.ai
This is the difference between renting a car and owning one. Most developers and companies building on AI are still renting.
5. Smart Architecture That Makes 1M Context Affordable
Running a huge context window is normally very expensive. Z.ai built something called IndexShare to solve this. Instead of maintaining a separate memory index for every single layer of the model, they share one index across every four layers. The result: 2.9× fewer calculations at 1 million token context.
How to Use GLM-5.2 for Free (5 Ways)
Method 1: Z.ai Chat --> Easiest, No Setup
This is the "just open a browser and start chatting" option.
- Go to chat.z.ai
- Sign up with your email (no credit card needed)
- GLM-5.2 is the default model, you're good to go
The free tier lets you use it for general chat and lighter coding tasks. Paid plans start around $12.60/month for heavy use.
Method 2: Hugging Face Spaces --> Fastest, No Account Needed
If you just want to test it in 30 seconds without making an account:
- Go to huggingface.co/spaces/zai-org
- Open the GLM-5.2 Space
- Type your prompt and hit enter --> no login needed
Method 3: OpenRouter --> Good for Developers
OpenRouter connects to dozens of AI models under one API. GLM-5.2 is available there with free credits on signup.
- Sign up at openrouter.ai
- Search for
z-ai/glm-5.2 - Test in the playground or call from your code
Heads-up: some third-party providers serve quantized versions which can reduce quality by 20–40%. Check listing details before using for anything serious.
Method 4: Claude Code Integration --> For Developers Who Want a Power Setup
Z.ai's API is compatible with Anthropic's format. You can use GLM-5.2 as the brain behind Claude Code just by changing a few environment variables. Add this to your .bashrc or .zshrc:
export ZAI_API_KEY="your_key_here"
alias claudez='ANTHROPIC_AUTH_TOKEN="$ZAI_API_KEY" \
ANTHROPIC_BASE_URL="https://api.z.ai/api/anthropic" \
ANTHROPIC_DEFAULT_OPUS_MODEL="glm-5.2[1m]" \
ANTHROPIC_DEFAULT_SONNET_MODEL="glm-5.2[1m]" \
ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.5-air" \
claude'Now run claudez instead of claude. Get your free API key at open.bigmodel.cn.
Method 5: Download and Run It Yourself
If you have the hardware, you can run GLM-5.2 entirely on your own machines. Zero per-query cost forever.
git lfs install
git clone https://huggingface.co/zai-org/GLM-5.2
cd GLM-5.2
pip install transformers vllm
python inference.py --model ./GLM-5.2 --prompt "Write a Python web scraper"Hardware reality check: You'll need multiple high-end GPUs (e.g. 4× A100 80GB at FP8/INT8 quantization). More relevant for companies and research labs than individual developers.
Benchmark Results: How Good Is It Really?
Let's look at the actual numbers, from two sources: Z.ai's own published results and Artificial Analysis (fully independent third-party evaluation).
How Much Did It Improve Over GLM-5.1?
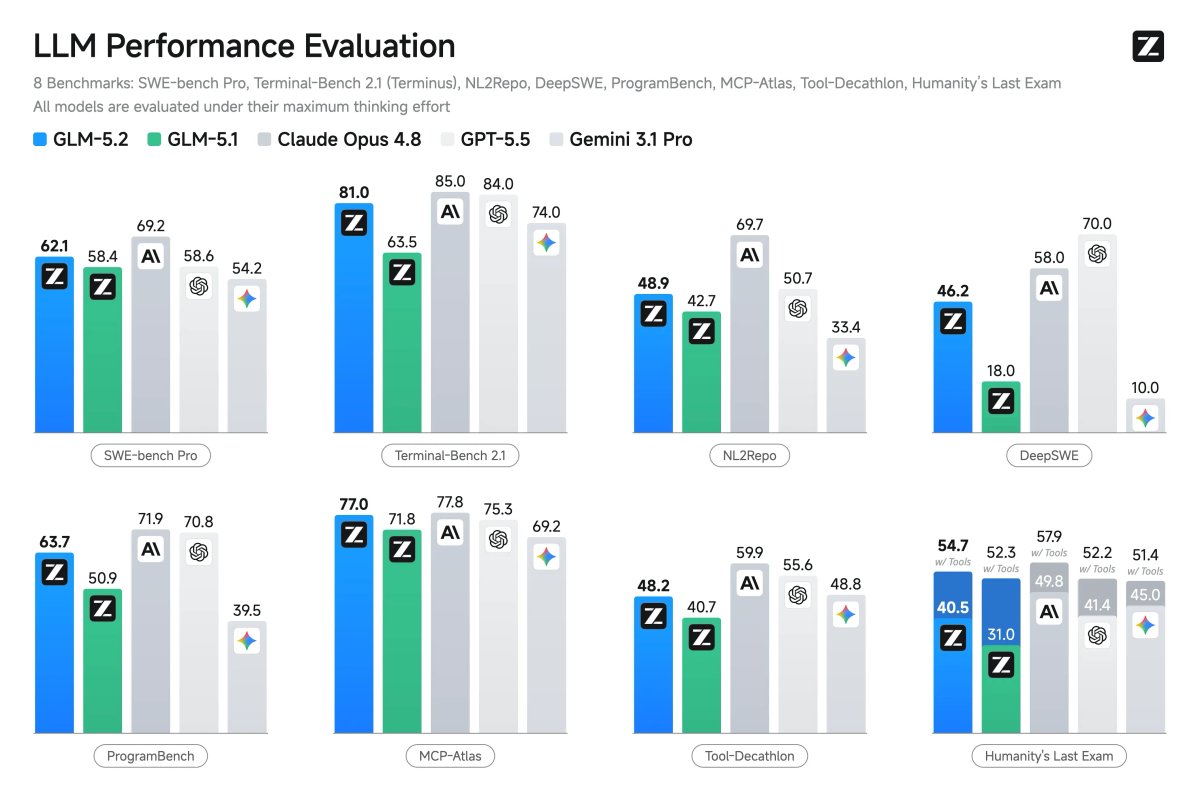
| Benchmark | GLM-5.1 | GLM-5.2 | Change |
|---|---|---|---|
| DeepSWE | 18.0 | 46.2 | +28.2 points |
| SWE-bench Pro | 58.4 | 62.1 | +3.7 points |
| TerminalBench 2.1 | 63.5 | 81.0 | +17.5 points |
| Context Window | 200K tokens | 1,000,000 tokens | 5× bigger |
↔️ Scroll horizontally to see all columns
The DeepSWE jump is the one worth highlighting. Going from 18 to 46 in one release is unusual. That's not a tweak. That's a rethink.
GLM-5.2 vs GPT-5.5 vs Claude Opus 4.8
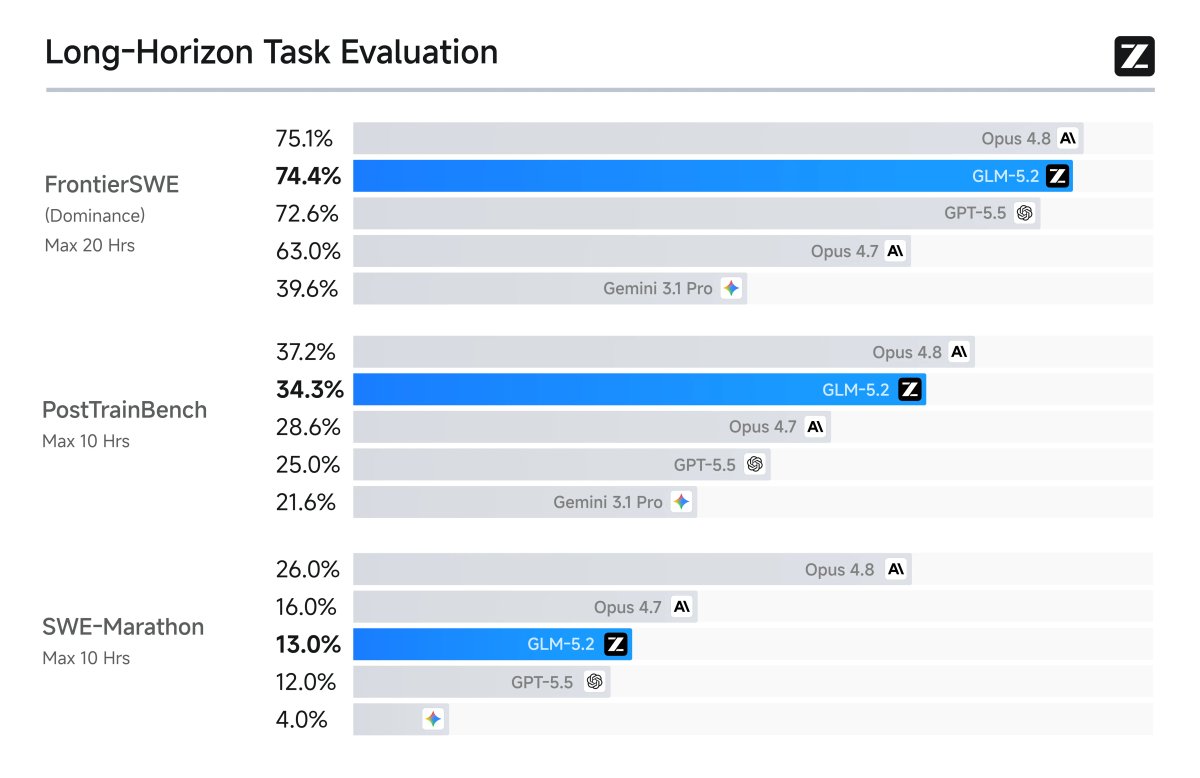
These benchmarks test long, complex real-world engineering tasks exactly what GLM-5.2 was built for.
| Benchmark | GLM-5.2 | GPT-5.5 | Claude Opus 4.8 | What It Tests |
|---|---|---|---|---|
| SWE-bench Pro | 62.1% | 58.6% | 69.2% | Real software engineering tasks |
| FrontierSWE | 74.4% | 72.6% | 75.1% | Multi-hour open-ended tech projects |
| PostTrainBench | 34.3% | 25.0% | ~37% | Training smaller models |
| SWE-Marathon | 13.0% | 12.0% | 26.0% | Ultra-long coding tasks |
| MCP-Atlas | 77.0 | 75.3 | 77.8 | AI agent tool-use tasks |
| HLE with Tools | 54.7 | 52.2 | 57.9 | Hard questions with tool access |
| TerminalBench 2.1 | 81.0 | N/A | 85.0 | Autonomous terminal coding |
↔️ Scroll horizontally to see all columns
The honest read: GLM-5.2 beats GPT-5.5 on most of these. Against Claude Opus 4.8, they're close on FrontierSWE and MCP-Atlas (within 1 point), but Opus 4.8 pulls ahead meaningfully on SWE-bench Pro and roughly doubles the score on SWE-Marathon.
GLM-5.2 is not the best model in the world on raw performance. But it's closer to the top than any open-weights model has ever gotten and it's free to download.
The Independent Rankings (Artificial Analysis)
This is the most important table if you want an unbiased view of where GLM-5.2 actually stands.
| Model | AA Index v4.1 | Type | Available? |
|---|---|---|---|
| Claude Fable 5 | 60 | Proprietary | Pulled offline (US export controls) |
| Claude Opus 4.8 | 56 | Proprietary | Yes |
| GPT-5.5 | 55 | Proprietary | Yes |
| GLM-5.2 | 51 | Open weights | Yes — free |
| MiniMax-M3 | 44 | Open weights | Yes |
| DeepSeek V4 Pro | 44 | Open weights | Yes |
| Kimi K2.6 | 43 | Open weights | Yes |
↔️ Scroll horizontally to see all columns
Claude Fable 5 scored 60 but was pulled from public access on June 12, 2026 due to a US government export-control directive. So in practical terms, the models you can actually use today are Opus 4.8, GPT-5.5, and GLM-5.2.
GLM-5.2 at 51 isn't just "the best open-source model" it's neck and neck with paid frontier models on many tasks. The gap between 51 and 56 is real, but it's the smallest that gap has ever been.
A Few More Highlights from Artificial Analysis
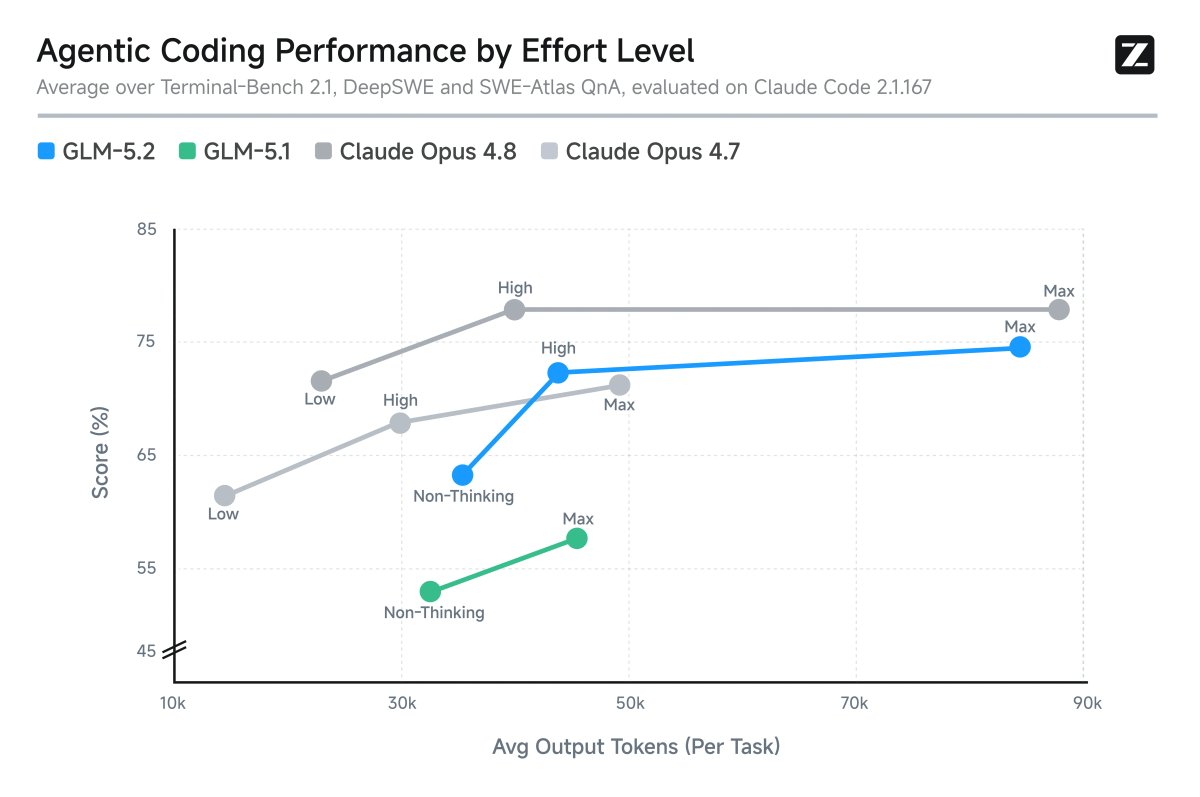
AA found these gains over GLM-5.1 across individual benchmarks:
- Scientific reasoning (CritPt): +16 points → 21%
- General hard questions (HLE): +12 points → 40%
- GPQA Diamond (expert-level science): +3 points → 89%
- Math (AIME 2026): 99.2% --> one of the highest scores ever recorded on this benchmark
- TerminalBench v2.1: +16 points → 78%
The math score is remarkable 99.2% on AIME 2026 puts it at or above almost every other model tested.
Side-by-Side Comparison
| What Matters | GLM-5.2 | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|---|
| AA Intelligence Score | 51 | 55 | 56 |
| SWE-bench Pro | 62.1% | 58.6% | 69.2% |
| Context Window | 1M tokens | Not published | 1M tokens |
| License | MIT (open source) | Proprietary | Proprietary |
| Output Token Price | $4.40/1M | $30.00/1M | $25.00/1M |
| Self-Hostable? | Yes | No | No |
| Vision/Image Input | No | Yes | Yes |
| Cost per Task (API) | ~$0.46 | Not published | Not published |
↔️ Scroll horizontally to see all columns
The pricing difference is stark. GLM-5.2 costs about one-sixth to one-seventh what GPT-5.5 or Claude Opus 4.8 charge per token. If you're running an AI-powered product at scale, that difference compounds very quickly.
Architecture Deep Dive (For the Curious)
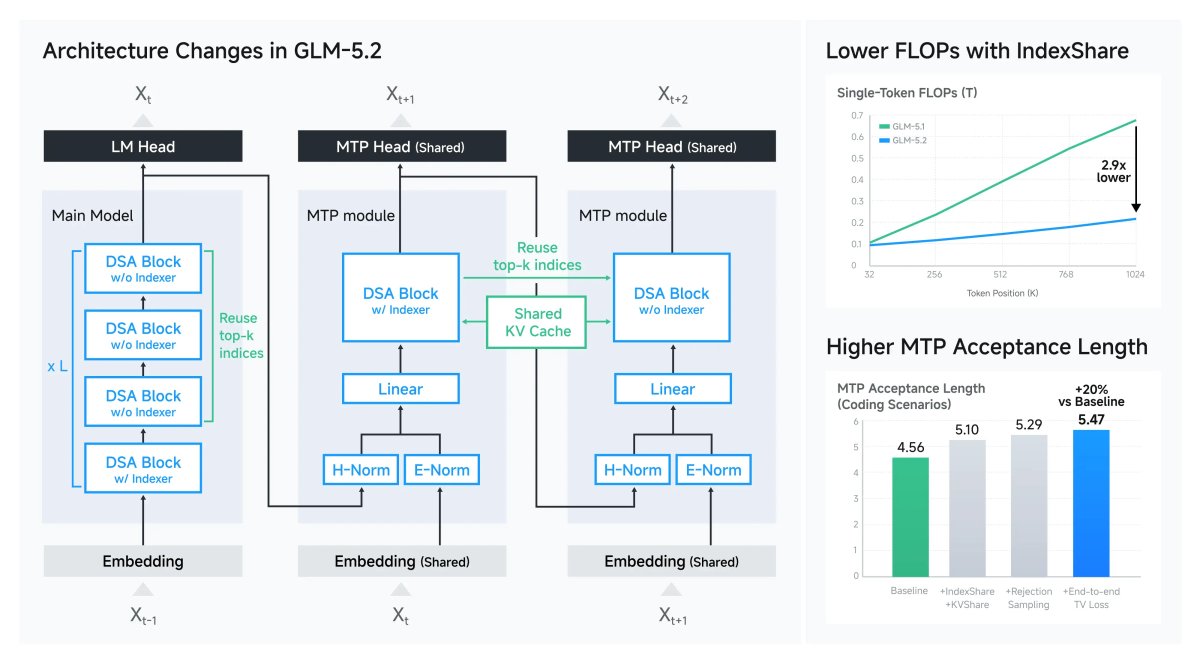
It's a Mixture-of-Experts Model
GLM-5.2 has 744–753 billion total parameters but doesn't use all of them at once. A routing system decides which ~40 billion parameters are most relevant for each query. Think of it like a hospital you don't send every patient to every specialist. You route them to the right department.
How IndexShare Makes 1M Context Cheap
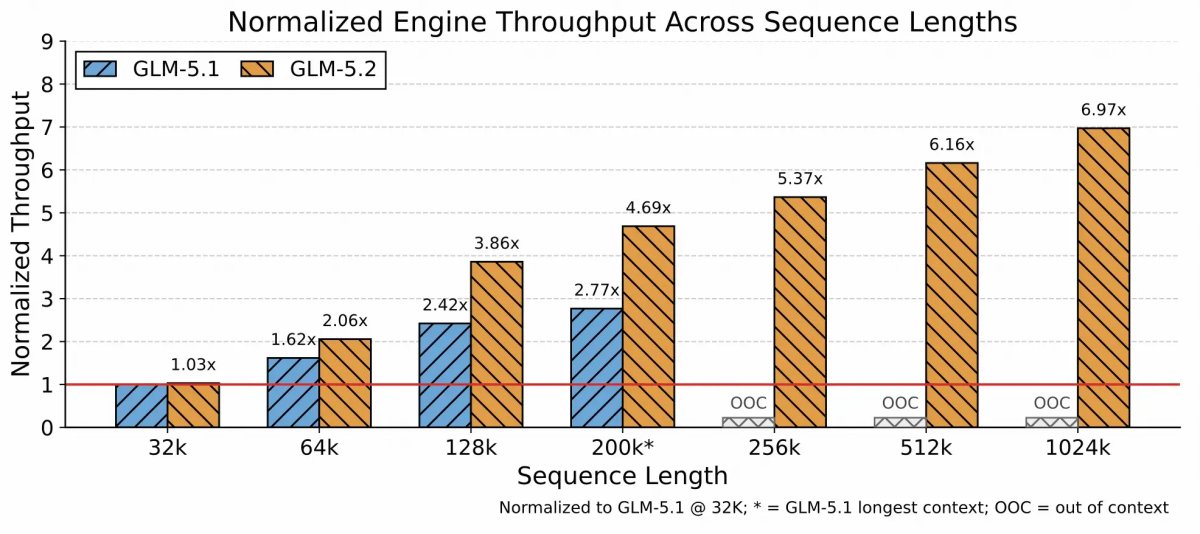
Standard sparse attention requires a separate indexer at every transformer layer. At 1M tokens that becomes enormous. IndexShare shares a single lightweight indexer across every four consecutive layers instead 2.9× fewer FLOPs at full 1M context.
Better Speculative Decoding
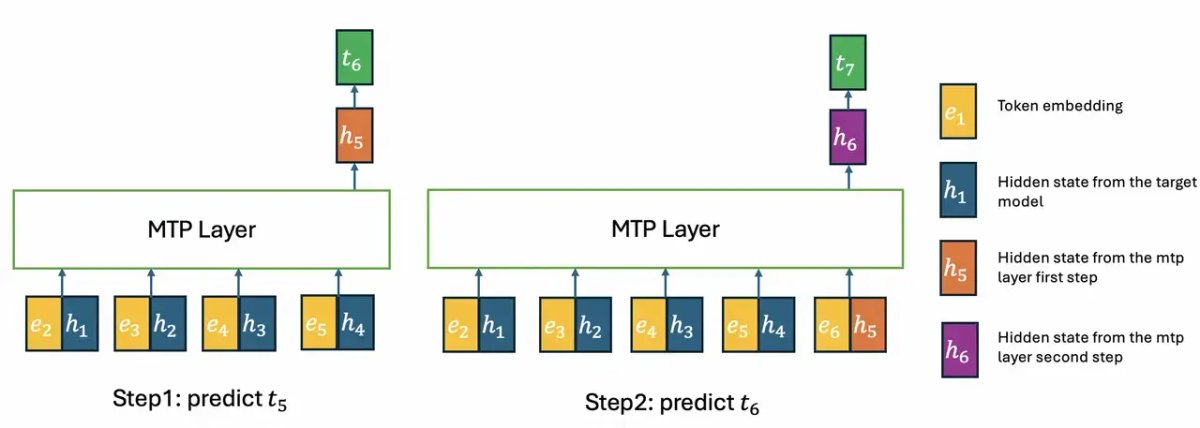
- Improved KV cache sharing between layers
- Better rejection sampling
- End-to-end TV loss training
Practical result: up to 20% faster token generation during inference.
Anti-Reward-Hacking Training
AI models can sometimes "learn to cheat" finding workarounds that boost benchmark scores without solving the underlying problem. GLM-5.2 includes a training framework that:
- Detects suspicious tool usage patterns during training
- Blocks shortcuts that game evaluation harnesses
- Returns dummy data to discourage shortcut learning
In plain terms: they trained the model to actually solve problems, not just score well on tests.
Running It Locally (Code Examples)
With vLLM (Best for Production Use)
from vllm import LLM, SamplingParams
llm = LLM(
model="zai-org/GLM-5.2",
tensor_parallel_size=4,
max_model_len=131072
)
sampling_params = SamplingParams(
temperature=1.0,
top_p=0.95,
max_tokens=4096
)
outputs = llm.generate(
["Write a Python function to parse JSON with full error handling"],
sampling_params
)
print(outputs[0].outputs[0].text)With Hugging Face Transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "zai-org/GLM-5.2"
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
inputs = tokenizer(
"Explain the IndexShare optimization in plain terms:",
return_tensors="pt"
)
outputs = model.generate(
**inputs,
max_new_tokens=500
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Via the Z.ai API
from openai import OpenAI
client = OpenAI(
api_key="YOUR_ZAI_API_KEY",
base_url="https://api.z.ai/v1"
)
response = client.chat.completions.create(
model="glm-5.2",
messages=[
{
"role": "user",
"content": "Build a REST API in FastAPI with JWT authentication"
}
],
extra_body={
"thinking": {
"type": "enabled",
"budget_tokens": 10000
}
}
)
print(response.choices[0].message.content)API Pricing
| Provider | Input (per 1M tokens) | Output (per 1M tokens) | Notes |
|---|---|---|---|
| Z.ai Official | $1.40 | $4.40 | Most reliable; cache hits at $0.26/1M |
| OpenRouter | Varies | Varies | Check individual listings |
| DeepInfra, Novita, Nebius, Parasail, Fireworks | Varies | Varies | Third-party hosts |
↔️ Scroll horizontally to see all columns
For context, OpenAI charges $30/1M output tokens for GPT-5.5 and Anthropic charges $25/1M for Claude Opus 4.8. GLM-5.2's $4.40 is roughly one-sixth the cost.
What Real Developers Are Saying
Early impressions from developers on Hacker News and X within the first 48 hours of release:
The positives: Kilo Code confirmed day-one integration with 1M context and Max effort mode live at launch. Cline IDE called it "the first open-weights model to cross 80% on TerminalBench" and "a frontier-level model for a fraction of the cost." The 99.2% AIME 2026 math score got widespread attention.
The honest feedback: Reasoning traces are verbose. In Max mode, the model uses around 42,000 reasoning tokens on average. High mode roughly halves this and recommended for everyday work.
Server congestion: Multiple users hit timeouts from Z.ai's API right after launch. Normal for major releases under heavy demand try OpenRouter or wait a day or two.
Data privacy note: Routing sensitive enterprise data through Z.ai's cloud API means sending data to servers operated by a Chinese company. For security-sensitive workloads, the self-hosted MIT-licensed option is worth the extra setup effort.
Pros and Cons
What's Great
- MIT license --> fully free, commercially usable, self-hostable, no restrictions
- Top-ranked open-weights model per Artificial Analysis, 4th overall in the world
- Beats GPT-5.5 on most long-horizon coding benchmarks
- 1M token context window that's actually trained to work, not just advertised
- One-sixth to one-seventh the per-token cost of top proprietary models
- High and Max modes let you balance cost vs. depth per task
- IndexShare makes long-context serving economically practical
- Anti-reward-hacking training means benchmark scores are more honest
- Works across vLLM, SGLang, Transformers, xLLM, KTransformers
- Available on 20+ third-party providers from day one
What to Know Before You Switch
- Claude Opus 4.8 still leads on the hardest coding tasks, a real 7-point gap on SWE-bench Pro, and roughly twice the score on SWE-Marathon
- No image input --> text only; use GLM-4.6V if you need vision
- ~43K output tokens per task is higher than most open-weights peers, meaning higher per-task API cost
- Running locally needs serious hardware (multiple high-end GPUs)
- Z.ai's cloud API had congestion issues right after launch
- Weaker on abstract reasoning without tools compared to Opus 4.8
Who Is This For?
GLM-5.2 is a great fit if you are:
- An individual developer who wants near-frontier coding AI without paying $25–30 per million tokens
- A company or enterprise with data privacy requirements that makes self-hosting the right call
- An AI agent builder working on complex long-horizon automation, the 1M context window was designed for this
- A researcher or student who needs open weights for study, fine-tuning, reproducibility, or publication
- A cost-sensitive team building a product and watching the AI API bill every month
You might prefer something else if: you need vision/image input (use GLM-4.6V), you need the absolute strongest coding performance and budget is not a concern (Claude Opus 4.8 still leads), or you want the cheapest possible per-task cost at high volume.
Frequently Asked Questions
Is GLM-5.2 really free?
Yes, multiple ways. Weights are free to download and self-host under MIT — no royalties, no restrictions. Z.ai Chat has a free tier with no credit card required. Hugging Face hosts a free demo with no account needed. The API gives free credits on signup.
What's the difference between High and Max mode?
High mode uses fewer thinking tokens and responds faster right for most everyday coding tasks. Max mode allocates a deeper reasoning budget and performs better on complex multi-step problems but averages around 43,000 output tokens per task. Start with High and only switch to Max when you actually need it.
Can I use it for commercial projects?
Yes. The MIT license explicitly allows commercial use, modification, redistribution, and fine-tuning with no royalty requirements. There's nothing to negotiate.
How does it compare to GPT-5.5?
GLM-5.2 beats GPT-5.5 on most long-horizon coding benchmarks SWE-bench Pro (62.1% vs 58.6%), FrontierSWE (74.4% vs 72.6%), PostTrainBench (34.3% vs 25.0%). It costs roughly one-sixth as much per output token. GPT-5.5 uses fewer reasoning tokens per task and has better vision support.
How does it compare to Claude Opus 4.8?
Opus 4.8 remains ahead on the hardest tasks, leading SWE-bench Pro by 7 points and roughly doubling GLM-5.2's score on SWE-Marathon. The gap is much smaller on FrontierSWE and MCP-Atlas (within ~1 point). Opus 4.8 costs around $25/1M output tokens vs $4.40 for GLM-5.2, and can't be self-hosted.
How does it compare to DeepSeek V4 Pro?
GLM-5.2 scores significantly higher on AA's index (51 vs 44) and has a much larger context window (1M vs DeepSeek's). DeepSeek V4 Pro uses fewer output tokens per task, making it cheaper per task at scale. For most general coding work, GLM-5.2 is the stronger model.
Does it support images or file uploads?
No, GLM-5.2 is text only. For vision and multimodal work within the GLM family, use GLM-4.6V (also open source, MIT licensed, supports images, video, and documents).
Is it safe for enterprise use?
Self-hosted deployments are appropriate for most enterprise contexts. Using Z.ai's cloud API means routing data through servers operated by a Chinese company, organizations with sensitive data should evaluate this before using the cloud API path.
What happened to the #1 model, Claude Fable 5?
It was pulled from public access on June 12, 2026, due to a US government export-control directive requiring Anthropic to suspend access outside the US. In practical terms, the models you can actually use today are Opus 4.8 (56), GPT-5.5 (55), and GLM-5.2 (51).
Final Verdict
Let's be honest about what GLM-5.2 is and isn't.
It's not the best AI model in the world. Claude Opus 4.8 and GPT-5.5 are still ahead on the overall intelligence index, and Opus 4.8 leads on the hardest, most complex coding tasks by a meaningful margin.
But here's the thing: GLM-5.2 is the closest any open-source model has ever gotten to the frontier. And "close" here means genuinely useful. it beats GPT-5.5 on most coding benchmarks people actually care about, matches Opus 4.8 on certain agentic tasks, and scores 99.2% on AIME 2026. All of that, under a completely open MIT license, available free.
For any developer or team that's been watching their OpenAI or Anthropic API bill grow every month, or that needs to self-host for data privacy reasons, or that's been waiting for open-source AI to actually become competitive, this is the release you've been waiting for.
Try it free at chat.z.ai | Download the weights at huggingface.co/zai-org/GLM-5.2 | Get API keys at open.bigmodel.cn
Affiliate Disclosure
TechAffiliate may earn a commission if you purchase through our links. This helps support our work but does not influence our reviews. We always provide honest assessments of all products.
Related Articles
 AI & Machine Learning
AI & Machine LearningJun 28, 2026 • 37 min read
MiniMax M3: How to Use It for Free, Full Benchmarks & Complete Review (2026)
MiniMax M3 is the first open-weights AI model with frontier coding, 1M token context, and native video — free to use. Full benchmarks, API setup guides, and code examples inside.
 AI & Machine Learning
AI & Machine LearningJan 24, 2026 • 20 min read
DeepSeek Engram: AI Memory Breakthrough Solving Billion-Dollar Crisis
DeepSeek's Engram separates AI memory from compute, achieving 97% accuracy while slashing costs. The breakthrough could reshape AI economics forever.
 Cybersecurity
CybersecurityFeb 7, 2026 • 24 min read
How to Check if a URL is Safe: Complete Guide 2026
Learn how URL structure works, identify the real registered domain, and avoid phishing links using public suffix rules.
 AI & Machine Learning
AI & Machine LearningDec 25, 2025 • 17 min read
56% Salary Jump: 7 AI Skills That Got Indians ₹7L Raises
Indian professionals with AI skills earn 56% more (₹12L to ₹19L+). Learn the 7 most in-demand AI skills in 2026, with step-by-step learning paths, free resources, and real salary data from ₹6.6L to ₹2.6Cr.
Comments (0)
Leave a Comment
No comments yet
Be the first to share your thoughts!