LongCat-2.0 Explained: Meituan's 1.6T Open-Weight AI Model Targeting GPT-5.5 and Claude
Aditya Kachhawa

A food delivery company just announced one of the largest AI models in the world right now.
Meituan, the Chinese giant best known for food delivery and local services, says it has built LongCat-2.0 — a 1.6 trillion-parameter Mixture-of-Experts AI model designed for coding, long-context reasoning, and agentic workflows.
But the most interesting part is not just the parameter count.
Meituan says LongCat-2.0 was trained and deployed on a 50,000-chip domestic Chinese compute cluster, making it a major signal in China's push for AI self-reliance. At the same time, the model is being positioned as open-weight and compared by Meituan with frontier models like GPT-5.5, Gemini, and Claude Opus on some coding and agent benchmarks.
That sounds huge — but it also needs careful explanation.
So in this article, let's break down what LongCat-2.0 actually is, what is confirmed from official sources, what is still a company claim, and what Indian developers, students, bloggers, and startups should really care about.
What Is LongCat-2.0?
LongCat-2.0 is Meituan LongCat's next-generation large language model. It is a large-scale Mixture-of-Experts (MoE) model with 1.6 trillion total parameters and around 48 billion activated parameters per token on average.
According to the official Hugging Face model card, LongCat-2.0 is a major step up from earlier LongCat models and includes architectural improvements for long-context and agentic workloads. The model card says pretraining covered more than 35 trillion tokens, and the training run had no rollbacks or irrecoverable loss spikes.
The model was also trained on hundreds of billions of tokens of 1-million-token-context data, which is why Meituan is positioning it for tasks like large codebase understanding, long document processing, and multi-step AI agent workflows.
One important caveat: the Hugging Face page currently says "Model weights coming soon." That means the model card and technical details are live, but full downloadable weights may not be available yet. Verify the current Hugging Face or GitHub status before assuming the model can be downloaded today.
Why LongCat-2.0 Is Trending Right Now
LongCat-2.0 is trending for three main reasons.
First, the scale is massive. A 1.6T-parameter model places LongCat-2.0 among the biggest open-weight-style AI model announcements in the world.
Second, the model is designed specifically for agentic coding. That means it is not only built to answer coding questions, but also to work through multi-step software tasks: reading files, planning changes, using tools, checking results, and correcting mistakes.
Third, Reuters reported that Meituan says the model was trained from scratch on a 50,000-chip domestic Chinese cluster, covering both training and inference. If independently verified, that would be a major milestone because training a trillion-parameter model is much harder than simply running one for inference.
This is why LongCat-2.0 is not just another AI model launch. It is also a story about AI chips, infrastructure, open-weight competition, and the future of coding agents.
LongCat-2.0 Key Specifications
| Spec | Detail |
|---|---|
| Model name | LongCat-2.0 |
| Developer | Meituan LongCat team |
| Model type | Large language model |
| Architecture | Mixture-of-Experts (MoE) |
| Total parameters | 1.6 trillion |
| Activated parameters | Dynamic range around 33B–56B per token, averaging ~48B |
| Context window | Up to 1 million tokens |
| Pretraining data | Official model card says 35T+ tokens; some launch materials describe 30T+ tokens |
| Long-context training | Hundreds of billions of tokens of 1M-context data |
| Main focus | Coding, long-horizon reasoning, AI agents, tool use |
| Training hardware | Meituan says 50,000 domestic Chinese chips / AI ASIC cluster |
| Weights status | Hugging Face says "Model weights coming soon" at time of writing |
| Access | Official LongCat site / API pages and OpenRouter are mentioned in launch materials; verify current availability |
↔️ Scroll horizontally to see all columns
Mixture-of-Experts Explained Simply
A normal dense AI model uses most or all of its parameters for every token it generates. That can become very expensive when models grow huge.
A Mixture-of-Experts model works differently. It has many expert networks inside it, but for each token, only some experts are activated. The model uses a routing system to decide which experts are needed for the current task.
Think of it like a hospital.
You do not need every doctor in the building to read an X-ray. You need the radiologist. In the same way, an MoE model tries to send each token to the right "expert" instead of waking up the whole model every time.
That is why LongCat-2.0 can have 1.6 trillion total parameters while activating only around 48 billion parameters per token on average.
1.6T Total Parameters vs 48B Active Parameters
This is one of the most important details to understand.
LongCat-2.0 has 1.6 trillion parameters stored in total, but not all of them are used at once. For each token, the model activates only a smaller portion — officially described around 48 billion active parameters on average, with launch materials also discussing a dynamic range of roughly 33B to 56B.
Why does that matter?
Because it gives the model large capacity without making every single answer as expensive as a fully dense 1.6T model. In simple words: LongCat-2.0 stores a huge amount of expert knowledge, but tries to spend compute only where it is needed.
This is especially useful for coding tasks, where one token may be simple, like a variable name, while another may require deeper reasoning, like designing a recursive algorithm or fixing a multi-file bug.
LongCat Sparse Attention: The 1M Context Trick
A 1-million-token context window means the model can work with a huge amount of information in a single session.
For example, it could potentially process:
- a large software repository,
- long legal documents,
- multiple research papers,
- a full product specification,
- or long-running agent conversations.
But long context is expensive. If a model attends to every token against every other token, the cost grows very quickly.
That is where LongCat Sparse Attention (LSA) comes in.
Meituan describes LSA as a sparse attention method designed to select important information instead of attending to every token equally. The idea is to reduce the compute burden of long-context processing so the model can handle 1M-token inputs more efficiently.
For readers, the practical meaning is simple: LongCat-2.0 is built for tasks where the model needs to "see the whole project," not just a small code snippet.
Zero-Compute Experts and ScMoE
One of the more technical details from the LongCat-2.0 launch is the idea of zero-computation experts and dynamic activation.
In real coding tasks, not every token needs the same amount of intelligence. A closing bracket, a function name, and a complex algorithmic decision do not require equal compute.
LongCat-2.0 uses a sparse MoE-style design where simple tokens can use less compute, while complex tokens can activate more expert capacity. Launch materials describe this as token-level dynamic activation, roughly in the 33B–56B active parameter range.
This matters because agentic coding is full of uneven complexity. Sometimes the model is reading boilerplate. Sometimes it is debugging logic across five files. A model that can dynamically allocate compute may be more efficient than one that treats every token the same.
MOPD: One Model With Agent, Reasoning, and Interaction Experts
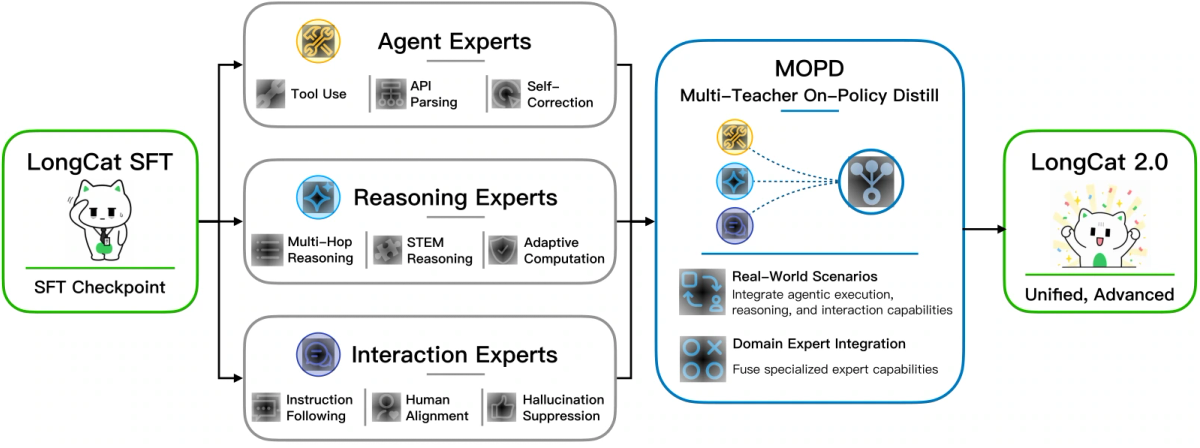
Another important detail is MOPD, which stands for Multi-Teacher On-Policy Distill.
In simple terms, LongCat-2.0 is not trained as one generic model only. The launch materials describe three major expert groups:
| Expert group | What it focuses on |
|---|---|
| Agent Experts | Tool use, API parsing, planning, self-correction |
| Reasoning Experts | Math, STEM, multi-hop reasoning, adaptive compute |
| Interaction Experts | Instruction following, alignment, hallucination reduction |
↔️ Scroll horizontally to see all columns
At inference time, a gating network can route a task toward the most useful expert group. For example, a coding-agent task may rely more on Agent Experts, while a math-heavy problem may lean more on Reasoning Experts.
This is important because modern AI models are no longer judged only by "Can it answer a question?" They are judged by whether they can complete a workflow.
Inference Optimization: Why It Matters for Real Developers
A 1.6T MoE model sounds impressive, but the real question is: can it run fast enough and cheaply enough for practical use?
LongCat's launch materials highlight several inference-side optimizations, including expert parallelism, communication optimization, and operator scheduling. These are not exciting marketing terms for normal users, but they matter a lot for latency and cost.
For example, if an AI coding agent is reading a large codebase and calling tools repeatedly, slow inference can make the entire workflow painful. Optimized expert routing and sparse attention can help reduce wasted compute.
For Indian startups and developers, this is the part to watch closely. If LongCat-2.0 becomes available through affordable APIs, the model could become interesting for large-context coding and document workflows. But until pricing, latency, and weight availability are clear, it is still a model to track rather than immediately build your whole stack around.
Benchmark Claims: Strong, But Still Need Independent Testing
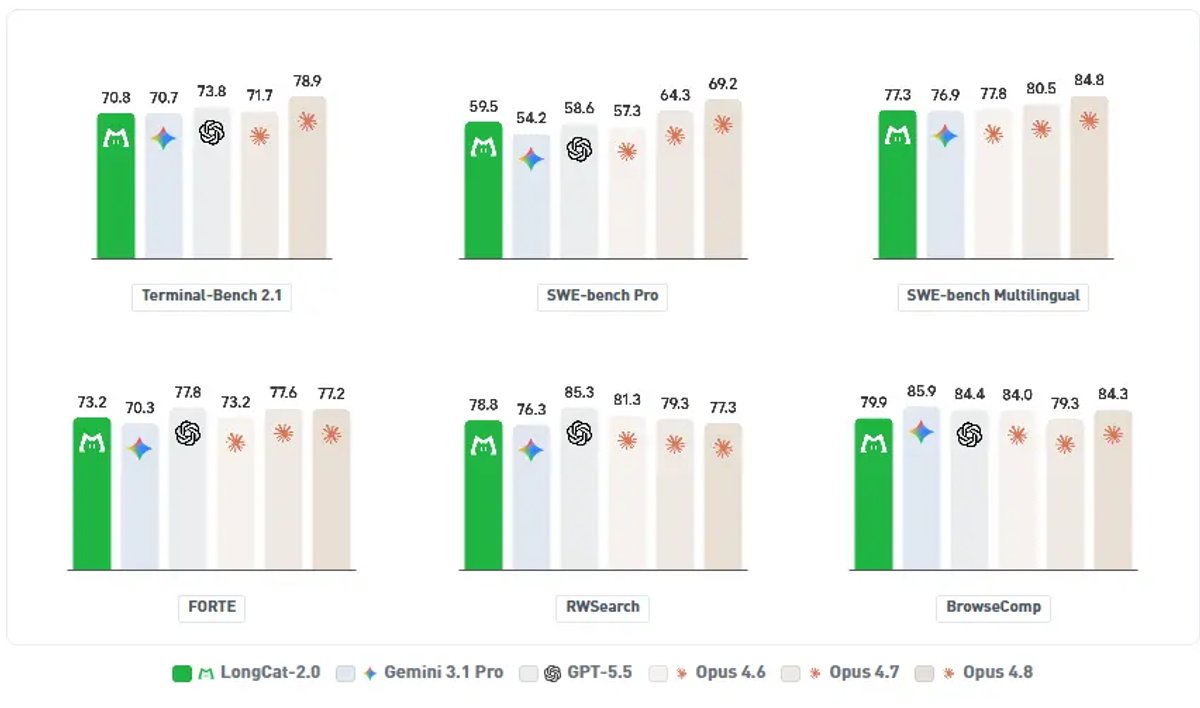
Meituan claims LongCat-2.0 performs strongly on coding and agent benchmarks. Some launch materials list results such as:
| Benchmark | Reported Score | What It Measures |
|---|---|---|
| SWE-bench Pro | 59.5 | Real software engineering tasks |
| SWE-bench Multilingual | 77.3 | Multilingual coding tasks |
| Terminal-Bench 2.1 | 70.8 | Terminal-based agent tasks |
| RWSearch | 78.8 | Search-agent evaluation |
| FORTE | 73.2 | Productivity / office-style tasks |
| BrowseComp | 79.9 | Complex browsing and retrieval tasks |
↔️ Scroll horizontally to see all columns
These scores are useful, but treat them carefully.
They are launch claims, not final proof. Independent researchers and developers still need to reproduce the results in their own environments. Self-reported benchmark numbers from any AI company — whether Chinese, American, or European — should always be seen as directional until third-party testing confirms them.
So the correct framing is not: "LongCat-2.0 beats GPT-5.5 and Claude."
The better framing is: Meituan claims LongCat-2.0 is competitive with frontier models on some coding and agent benchmarks, but independent verification is still needed.
Can LongCat-2.0 Really Compete With GPT-5.5 and Claude?
According to Reuters, Meituan says LongCat-2.0 matched or exceeded several leading proprietary models, including Gemini, GPT-5.5, and Claude Opus, on some coding and agent benchmarks.
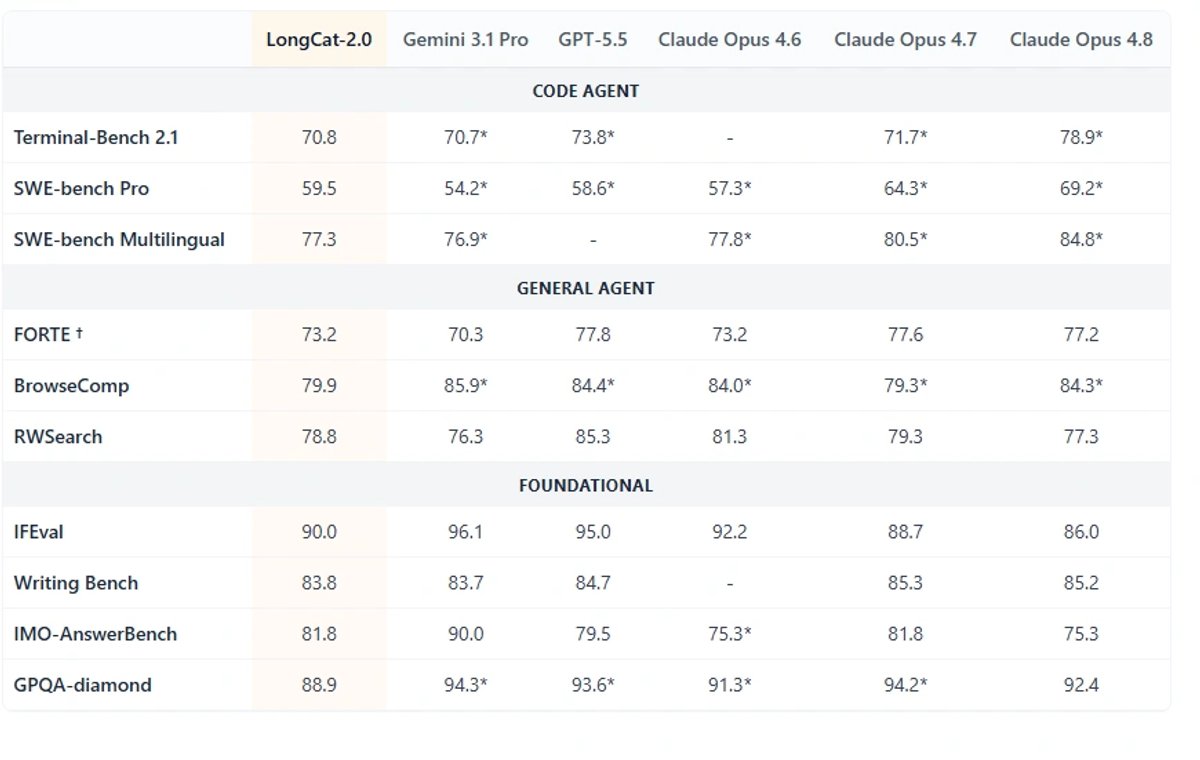
That is a strong claim, but it does not mean LongCat-2.0 is automatically better than GPT-5.5 or Claude in every use case.
Closed frontier models are usually evaluated across many categories: coding, tool use, reasoning, writing, multimodal tasks, factual reliability, safety behavior, latency, and real-world product stability. LongCat-2.0 may be very strong in agentic coding, but broader performance needs independent testing.
A fair way to say it is this:
LongCat-2.0 is now in the conversation for frontier-style coding and agentic AI, but the comparison with GPT-5.5 and Claude is not settled yet.
Real-World Use Cases Meituan Highlights
The LongCat-2.0 launch materials focus heavily on practical agent workflows, not just chat.
Some highlighted examples include:
| Use Case | What It Means in Simple Words |
|---|---|
| AI SQL Agent | Business users ask questions in natural language, and the AI plans SQL-style data queries |
| Codebase migration | The model reads old code and new SDK docs, then helps migrate the project |
| Full app development | It generates architecture, logic, and UI from a short product idea |
| 3D interactive demos | It can generate single-file Three.js-style interactive demos from natural language |
| AI novel factory | Multiple AI agents coordinate world-building, chapter generation, review, and revision |
↔️ Scroll horizontally to see all columns
These examples show why LongCat-2.0 is being marketed as an agentic coding model, not just a chatbot.
For developers, the most interesting use case is codebase migration. If a model can read a large repo, understand architecture, compare it with new documentation, and refactor safely, that is far more valuable than simply generating a small function.
Why Training on Domestic Chinese Chips Matters
This is arguably the biggest story behind LongCat-2.0.
Reuters reported that Meituan says LongCat-2.0 was trained from scratch using 50,000 domestic Chinese chips and can process inputs of up to 1 million tokens. Reuters also noted that Meituan did not name the specific chipmaker.
Why does this matter?
Because training a trillion-parameter AI model is one of the hardest compute tasks in technology. It requires not only chips, but also networking, software, memory management, fault recovery, and stable distributed training.
China has faced restrictions on access to cutting-edge US AI chips since 2022. If Meituan's claim is independently confirmed, LongCat-2.0 would be a major signal that domestic AI infrastructure is becoming more capable.
Still, readers should remember: the exact chip supplier has not been officially disclosed, and the full training story should be treated as a company claim until more technical audits or third-party analysis arrive.
What Is Confirmed vs What Is Still Unverified?
To keep things clear, here is the safest way to understand LongCat-2.0.
Confirmed from official model materials
- LongCat-2.0 is a large-scale MoE language model.
- It has 1.6T total parameters.
- It activates around 48B parameters per token on average.
- The Hugging Face model card says pretraining spanned 35T+ tokens.
- The model was trained with hundreds of billions of tokens of 1M-context data.
- LongCat Sparse Attention is used for long-context capability.
- The model is focused on coding and agentic tasks.
- Hugging Face currently says model weights are coming soon.
Reported by Reuters as Meituan's claim
- LongCat-2.0 was trained from scratch on a 50,000-chip domestic Chinese cluster.
- It was trained and run on domestic hardware.
- It can process up to 1 million input tokens.
- Meituan claims it matches or exceeds some proprietary models on some coding and agent benchmarks.
Still needs verification
- Exact chipmaker used in the training cluster.
- Independent benchmark reproduction.
- Final weight release timing.
- Final license terms for commercial use.
- API pricing and global availability.
- Real-world performance outside Meituan's own demos.
What LongCat-2.0 Means for Indian Developers
For Indian developers, LongCat-2.0 is worth watching for three reasons.
First, it shows that open-weight coding models are becoming more serious. If models like LongCat-2.0, MiniMax M3, GLM-5.2, and DeepSeek-style releases keep improving, developers may get more alternatives to expensive closed APIs.
Second, the 1M context window is useful for real software work. Many developers do not need another chatbot. They need a model that can understand a full repo, documentation, issue history, logs, and test failures together.
Third, agentic coding is where AI tools are moving. The future is not only "ask AI a question." It is "give AI a task and let it plan, execute, test, and fix."
That said, individual developers should not expect to self-host a 1.6T MoE model on normal hardware. Even with sparse activation, this is a datacenter-scale model. Most users will likely access it through APIs or hosted platforms if availability expands.
Should You Care About LongCat-2.0?
Developers: Yes, especially if you work with large codebases, migration tasks, debugging, or AI agents. But wait for independent tests before replacing your current coding model.
Students: Yes, because it is a great case study in MoE architecture, sparse attention, long-context training, and AI infrastructure.
Startup founders: Yes, but as a future option. If pricing becomes competitive, LongCat-2.0 could be useful for coding assistants, document AI, and internal workflow automation.
Bloggers and affiliate marketers: Definitely. This is a high-interest topic with multiple follow-up articles: benchmark updates, API access, LongCat vs MiniMax M3, LongCat vs GLM-5.2, and LongCat vs Claude.
AI researchers: Yes. The most interesting part may be the domestic compute story and the technical design around sparse attention, dynamic activation, and multi-expert post-training.
Limitations You Should Mention
LongCat-2.0 is exciting, but it is not a magic replacement for every AI model.
Key limitations:
- Full model weights may still be unavailable.
- Benchmark scores are mostly launch/company claims.
- The chipmaker behind the 50,000-chip cluster is not disclosed.
- API pricing and global access need verification.
- Self-hosting will likely require serious infrastructure.
- Real-world reliability must be tested on actual coding tasks.
Final Verdict
LongCat-2.0 is one of the most important AI model announcements of 2026 so far — not because it definitely beats GPT-5.5 or Claude, but because of what it represents.
It combines a 1.6T-parameter MoE architecture, dynamic 33B–56B activation, 1M context support, LongCat Sparse Attention, MOPD multi-expert post-training, and a major claim of training on 50,000 domestic Chinese chips.
If Meituan's infrastructure claims and benchmark results hold up under independent testing, LongCat-2.0 could become a serious open-weight competitor in agentic coding and long-context AI workflows.
For now, the smartest position is simple: watch it closely, verify weight availability, test it when access opens up, and do not treat launch benchmarks as final truth.
LongCat-2.0 is not just another AI model. It is a signal that the open-weight, long-context, agentic coding race is getting much more serious.
FAQs
1. What is LongCat-2.0?
LongCat-2.0 is a 1.6 trillion-parameter Mixture-of-Experts language model from Meituan's LongCat team. It is built for coding, long-context reasoning, and agentic AI workflows.
2. Who created LongCat-2.0?
LongCat-2.0 was created by Meituan's LongCat team, which was founded inside the Chinese food delivery and local-services company.
3. How many parameters does LongCat-2.0 have?
LongCat-2.0 has 1.6 trillion total parameters and activates around 48 billion parameters per token on average, with launch materials describing a dynamic range of roughly 33B–56B.
4. What is LongCat Sparse Attention?
LongCat Sparse Attention is a sparse attention method designed to help the model handle 1-million-token context more efficiently by focusing on important information instead of attending to every token equally.
5. What is MOPD in LongCat-2.0?
MOPD stands for Multi-Teacher On-Policy Distill. It is a post-training approach that combines Agent Experts, Reasoning Experts, and Interaction Experts into one model.
6. Can LongCat-2.0 process 1 million tokens?
Yes, LongCat-2.0 is described as supporting up to 1 million tokens of context. This is useful for large documents, codebases, and long-running agent tasks.
7. Was LongCat-2.0 trained on Nvidia chips?
Reuters reported that Meituan says LongCat-2.0 was trained from scratch on a 50,000-chip domestic Chinese compute cluster. The exact chipmaker has not been officially named.
8. Does LongCat-2.0 beat GPT-5.5 and Claude?
Meituan claims LongCat-2.0 matches or exceeds some proprietary models on some coding and agent benchmarks. However, this is not yet independently verified across the board.
9. Can I download LongCat-2.0 now?
At the time of writing, the Hugging Face page says "Model weights coming soon." Check the official Hugging Face or GitHub page before assuming full download access.
10. Is LongCat-2.0 useful for Indian developers?
Yes, especially for developers interested in large-codebase understanding, AI coding agents, and long-context automation. But most users will likely need hosted API access rather than self-hosting.
Related Reading
- MiniMax M3 Review: https://www.techaffiliate.in/blog/minimax-m3-free-benchmarks-review-2026
- GLM-5.2 Review: https://www.techaffiliate.in/blog/glm-5-2-how-to-use-free-benchmarks-review
- 7 Free AI Tools for Indian Students: https://www.techaffiliate.in/blog/7-free-ai-tools-for-indian-students-2026
External Sources
- Official LongCat-2.0 blog: https://longcat.ai/blog/longcat-2.0/
- Official LongCat-2.0 Hugging Face model card: https://huggingface.co/meituan-longcat/LongCat-2.0
- Reuters report: https://www.reuters.com/world/china/chinas-meituan-says-new-ai-model-trained-domestic-chips-2026-06-30/
- Official LongCat GitHub organization: https://github.com/meituan-longcat
Would you try LongCat-2.0 over GPT-5.5 or Claude if the API becomes cheaper and independent benchmarks confirm the claims? Let us know in the comments.
Affiliate Disclosure
TechAffiliate may earn a commission if you purchase through our links. This helps support our work but does not influence our reviews. We always provide honest assessments of all products.
Related Articles
 AI & Machine Learning
AI & Machine LearningDec 30, 2025 • 16 min read
DeepSeek vs ChatGPT vs Gemini 2026: Which AI is Better? (Tested 30 Days)
Gemini topped India's AI searches in 2025. I tested GPT-5.2, Gemini 3 Flash, and DeepSeek V3.2 for 30 days. Real results, privacy warnings, honest winner.
 Tech News
Tech NewsDec 19, 2025 • 4 min read
India Just Beat USA: 65 Million Daily ChatGPT Users - How Free AI Made India #1 Global Market
India now has 65 million daily ChatGPT users—more than double the USA's 31 million. A massive 607% growth makes India the world's largest AI market. Free platforms, ₹150/month data, and 700M mobile users fueled this revolution. Full breakdown inside.
 AI & Machine Learning
AI & Machine LearningDec 11, 2025 • 10 min read
What is Agentic AI? The Technology Replacing Apps in 2026 - Complete India Guide
Agentic AI isn't ChatGPT 2.0... it's something far more powerful. Discover how AI agents are replacing traditional apps in 2026, and why 200,000+ Indian IT professionals are already using this technology at TCS, Infosys, Wipro, and Cognizant. Complete guide for students and professionals.
Comments (0)
Leave a Comment
No comments yet
Be the first to share your thoughts!